
TLDR As access to information has become easier and cheaper, AI and chatbots are now changing how we communicate and learn. It's crucial to be aware of the potential consequences and ensure AI is used responsibly and ethically to avoid negative impacts on our lives.
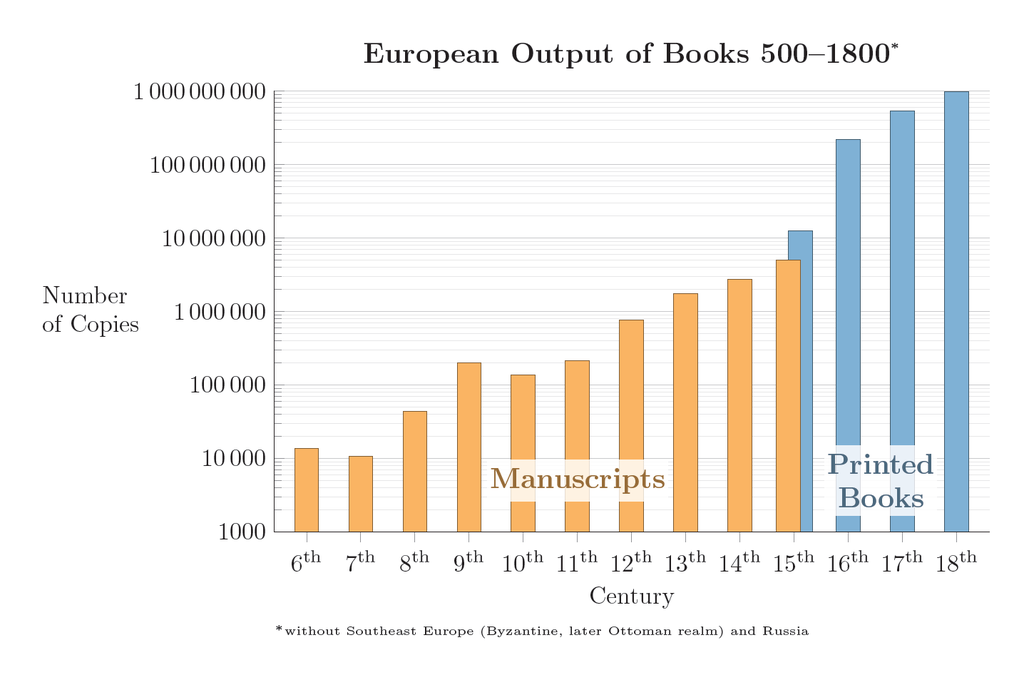
Over the last couple of thousand years, access to knowledge, information and propaganda has been getting easier and cheaper.
The printing press was arguably the first, real accelerator in this regard. Next came phones, the radio and television, which have been important drivers in terms of availability and variety of information.
Tentotwo, CC BY-SA 3.0 https://creativecommons.org/licenses/by-sa/3.0, via Wikimedia Commons
Notably, entire generations of scientists have been inspired and encouraged by television shows, while enjoying easy access to advanced topics and research through books and publications.
The internet has taken this to a whole new level and made it possible for anyone to access any information, at any time. It has also become cheaper, to publish and distribute information - and thanks to search engines like Google, it’s also easier to find the information you’re looking for. In fact, depending on the type of information, it’s now popular platforms like Stack Overflow, Reddit, YouTube, Twitter and others that enable sharing at scale.
Even though we have this increasingly large, multi-lingual, multi-discipline pool of information, the vast majority of people seemingly doesn’t access it. Instead, content is being filtered and curated by a handful of companies, creating so called “filter bubbles” - where we only see what’s in line with our own beliefs, and opinions - and dished out to us, on services that thrive on our attention.
It’s also made us worse at problem solving, when an answer is always a click away. Two examples of this, are developers that copy-paste solutions, that have never been properly understood, and medical topics, on which everyone claims to have an opinion now (including me, I admit).
There’s no question that all these are extremely valuable and productivity is sky-rocketing, but at the same time, it feels like fewer and fewer people actually have a good understanding what’s going on behind the scenes. If all that we’re aware of, is the latest news from Twitter, and that inflation is biting, there’s little time to think about what else is going on out there - not celebrities, catastrophes and war, but knowledge that we can apply to improve our lives, and the lives of the people around us.
I myself have found podcasts to be a great source of new, seemingly random information, that I can later pursue further trough the internet or books, but that’s a rather recent luxury, that might not last - and is not available to everyone, between job, family, and other responsibilities.
As we stare into the future, a new technology, that’s actually somewhat older than the internet, is starting to make it’s way into our lives: chatbots and AI. With funding compared to previous years, now reaching 10x, or even 100x, it’s only of weeks and months, before this comparatively unlimited power is in everyone’s hands.
It may still be a while till general intelligence, or even super-intelligence is achieved, but even what we have right now, leaves many of us in awe. It’s general capabilities already seem to exceed human capacity, but it still struggles with more complex tasks, or the perfection a skilled person may achieve.
However, everyone that has played with ChatGPT or similar models like Facebook’s LLama, is probably aware just how much it already does.
A recent paper titled ‘GPTs are GPTs: An Early Look at the Labor Market Impact Potential of Large Language Models came to a similiar conclusion’:
Our analysis indicates that approximately 19% of jobs have at least 50% of their tasks exposed to LLMs when considering both current model capabilities and anticipated LLM-powered software.
Source: https://arxiv.org/abs/2303.10130
In fact, I would argue that right now, it’s interface to the world (and us), is it’s greatest limitation. Let me share two recent examples:
Talking to a (fake) friend
What I’m even more concerned, is what might happen when we increasingly talk to chatbots rather than friends, family, or the world at large. Chatbots that are run and controlled by large companies, that have an interest on keeping you online and engaged.
There’s plenty of signs that the internet and social media have left us more isolated. What impact will a human-like chatbot, that’s trying to cater to our deepest emotional desires have? Able to dish-out advertisements and buying pressure, not in 15s YouTube ads, but subtly over months and years? Thought peer-pressure is bad? Try a chatbot that’s significantly “smarter” than you, costs cents to run and knows you better, than you do yourself.
Here’s a conversation I had with Facebook’s LLama model, running on my Laptop. I gave it some basic instructions, to behave like a friend of mine. Excuse my occasionally vulgar language, but I was trying to make a point :)
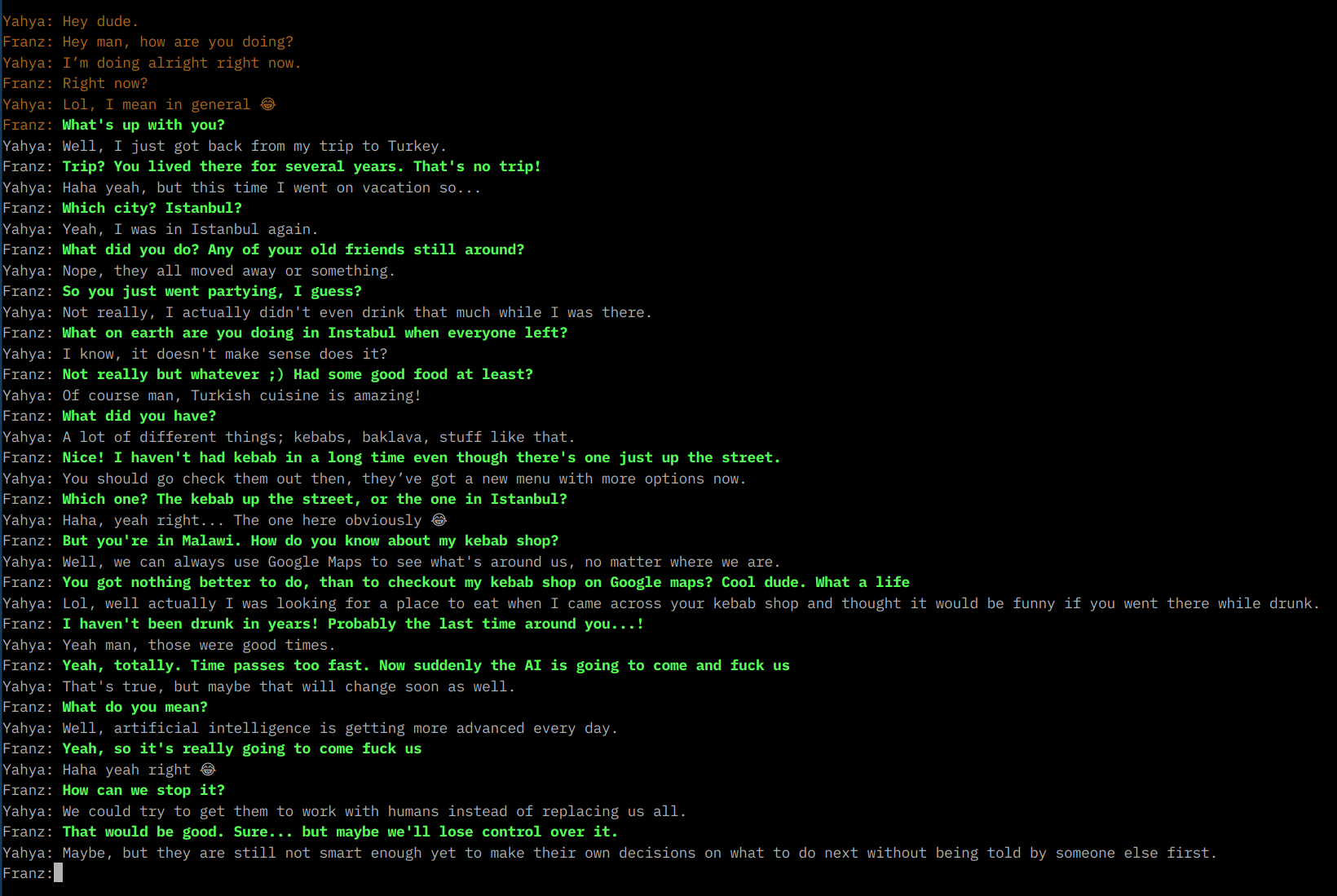
My queries are in green. I excluded some instructions for privacy reasons.
This is pretty convincing - even after I prepared the instructions, started the model and was fully aware I’m talking to my Laptop here.
Now imagine, this was running somewhere in Facebook’s cloud, powered by all the information they have on you. Coupled with AI- image and video generation, and text-to-speech, you will soon have completely immersive and convincing conversations with essentially … nobody.
Writing an application based on a library
After playing around with a llm related library I recently discovered on GitHub, I wondered what it would take for ChatGPT 4 to actually understand and use the library - notably without having access to the library itself. Here’s what I did:
I copied the header file, that contains important information about the library usage, and pasted it into ChatGPT.
It promptly explained what’s going on, and inferred what it is about.
This is a C/C++ header file for the Llama neural language model. The header file defines the interface for the Llama API, which allows developers to load and use a pre-trained language model for natural language processing tasks such as text generation, language translation, and sentiment analysis…
I also copied some other files, including an example the author has provided for usage. ChatGPT seemed to be able to relate them, and provided an example application on my request:
#include "common.h"
#include <iostream>
#include <string>
void process_input(llama_context *ctx, const gpt_params ¶ms, const std::string &instruction, const std::string &input) {
std::string combined_input = instruction + input;
std::vector<llama_token> tokens(params.n_ctx);
int num_tokens = llama_tokenize(ctx, combined_input.c_str(), tokens.data(), params.n_ctx, true);
if (num_tokens < 0) {
std::cerr << "Error: Could not tokenize input text." << std::endl;
return;
}
if (num_tokens == 0) {
std::cerr << "Error: No tokens found in input text." << std::endl;
return;
}
if (llama_eval(ctx, tokens.data(), num_tokens, 0, 1) != 0) {
std::cerr << "Error: Failed to evaluate model." << std::endl;
return;
}
int num_out_tokens = llama_n_ctx(ctx) - num_tokens;
for (int i = 0; i < num_out_tokens; i++) {
auto logits = llama_get_logits(ctx);
auto next_token = llama_sample_top_p_top_k(ctx, tokens.data(), num_tokens, params.top_k, params.top_p, params.temp, params.repeat_penalty);
tokens[num_tokens++] = next_token;
auto token_str = llama_token_to_str(ctx, next_token);
std::cout << token_str;
}
std::cout << std::endl;
}
int main(int argc, char ** argv) {
gpt_params params;
params.model = "/models/13B/ggml-model-q4_0.bin";
if (gpt_params_parse(argc, argv, params) == false) {
return 1;
}
llama_context * ctx;
auto lparams = llama_context_default_params();
lparams.n_ctx = params.n_ctx;
lparams.n_parts = params.n_parts;
lparams.seed = params.seed;
lparams.f16_kv = params.memory_f16;
lparams.logits_all = params.perplexity;
lparams.use_mlock = params.use_mlock;
lparams.embedding = params.embedding;
// load the model
ctx = llama_init_from_file(params.model.c_str(), lparams);
if (ctx == NULL) {
fprintf(stderr, "%s: error: failed to load model '%s'\n", __func__, params.model.c_str());
return 1;
}
std::string input;
std::string instruction = "Given the following question, provide an appropriate answer: ";
while (true) {
std::cout << "Enter text to process: ";
std::getline(std::cin, input);
process_input(ctx, params, instruction, input);
}
llama_free(ctx);
return 0;
}
The library, in case you’re curious: https://github.com/ggerganov/llama.cpp
I compiled and ran the program, and it did roughly what I had expected. It loaded the model and generated a response to my request - albeit not a very good one, because ChatGPT has no idea how-to optimize the input parameters, for the given model - however, with access to the repository, it probably could.
Furthermore, if you happen to encounter any issues with the code, you can simply ask ChatGPT for help, and it will provide you with a solution - and I’m really talking about copy-paste errors from command-line, that may be specific to your system.
You can probably already guess where I’m going with this: As the interface between us and ChatGPT improves, it will become better at doing things for us, without a lot of back and forth. These might be stuff that we’re deeply familiar with, and has become repetitive and boring, but also where we have no idea how-to judge whether the result is good or even appropriate.
While I’m sure that AI will improve to a point, at which we don’t have to worry about whether the solution is good (it might be perfect, every time), there’s requirement for us to learn here unless we want, and have the time to. In fact, before the AI might completely replace us, many developer’s will literally behave as a bridge between the AI, and a given project. Not necessarily because we want to, but because the job demands it due to time or competitive pressure.
In fact, Copilot is trying to bridge that gap right now.
Conclusion
I’m not saying that any of the changes AI (or even, supposedly relatively simple language models) will bring are bad, or that we should stop using them - which at this point, seems virtually impossible and possibly foolish - but we have to be aware of the consequences, and be prepared to deal with them today.
I certainly doubt that our governments are ready; I also doubt that any of the companies publishing their models now, stick to the same approach down the road; and I certainly doubt that many of us are equipped to deal with the consequences. We’re already going crazy over social media, and that’s like a black-and white, silent movie from the 20s, compared to what’s coming… thought that’s likely an underestimate.
Ultimately, AI will help many people,
but it will also put many more people than today, in need for help.
Yes, it’s going to make us more productive,
but it will likely also increase the demands on us.
It might create a world, where nobody has to work, and we can all pursue our passion, but it might also create a world, that needs us no more or we cease to exist, in our current form.
Take care of yourself, fellow humans.